1. Setting for Zeppelin¶
You can try LightningDB in the Zeppelin notebook.
Firstly, deploy and start the cluster of LightningDB using Installation before launching the Zeppelin daemon.
Secondly, to run LightningDB on the Spark, the jars in the LightningDB should be passed to the Spark.
When EC2 Instance is initialized, the environment variable ($SPARK_SUBMIT_OPTIONS) is configured for this reason.
Thus just need to check the setting in zeppelin-env.sh.
$ vim $ZEPPELIN_HOME/conf/zeppelin-env.sh
...
LIGHTNINGDB_LIB_PATH=$(eval echo $(cat $FBPATH/config | head -n 1 | awk {'print $2'}))/cluster_$(cat $FBPATH/HEAD)/tsr2-assembly-1.0.0-SNAPSHOT/lib/
if [[ -e $LIGHTNINGDB_LIB_PATH ]]; then
export SPARK_SUBMIT_OPTIONS="--jars $(find $LIGHTNINGDB_LIB_PATH -name 'tsr2*' -o -name 'spark-r2*' -o -name '*jedis*' -o -name 'commons*' -o -name 'jdeferred*' -o -name 'geospark*' -o -name 'gt-*' | tr '\n' ',')"
fi
...
Finally, start Zeppelin daemon.
$ cd $ZEPPELIN_HOME/bin
$ ./zeppelin-daemon.sh start
2. Tutorial with Zeppelin¶
After starting zeppelin daemon, you can access zeppelin UI using a browser. The URL is https://your-server-ip:8080.
Tip
We recommend that you proceed with the tutorial at the Chrome browser.
There is a github page for tutorial.
The repository includes a tool for generating sample csv data and a notebook for the tutorial.
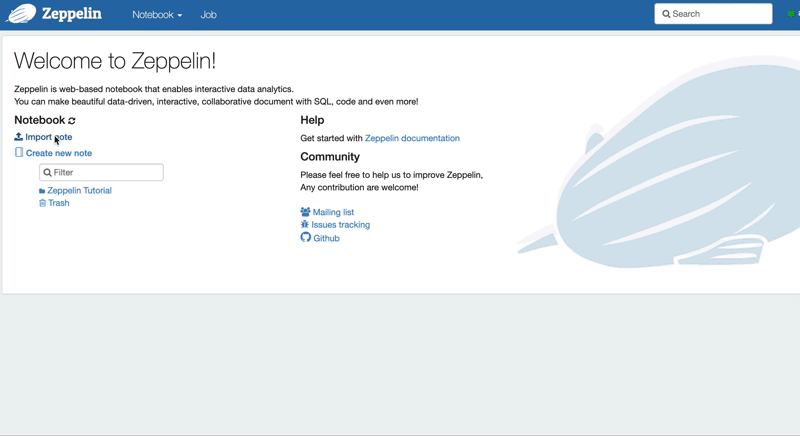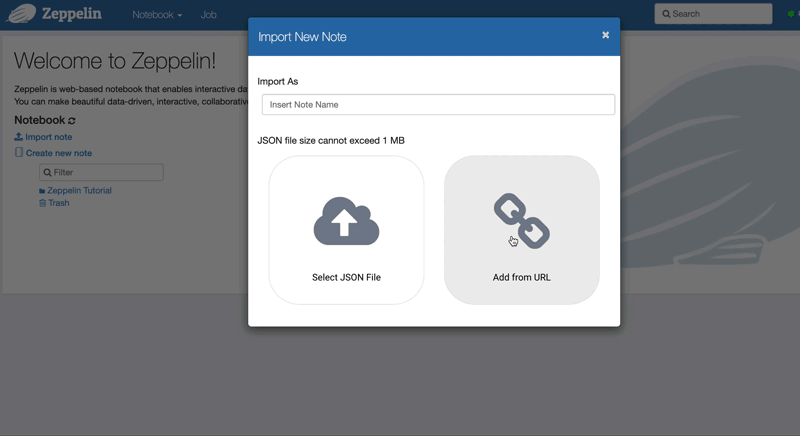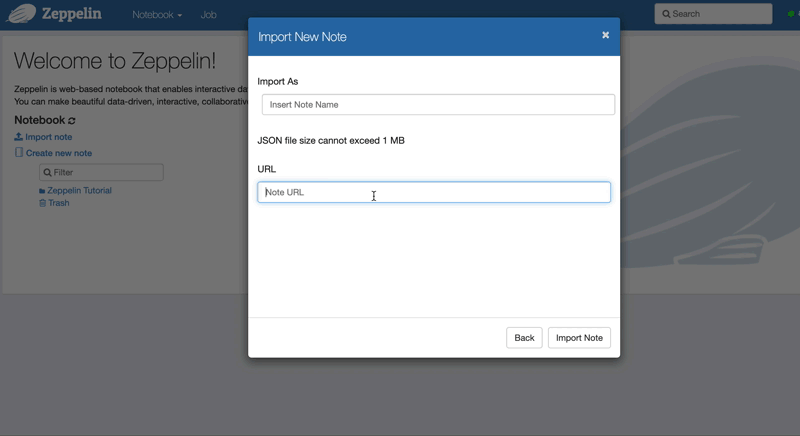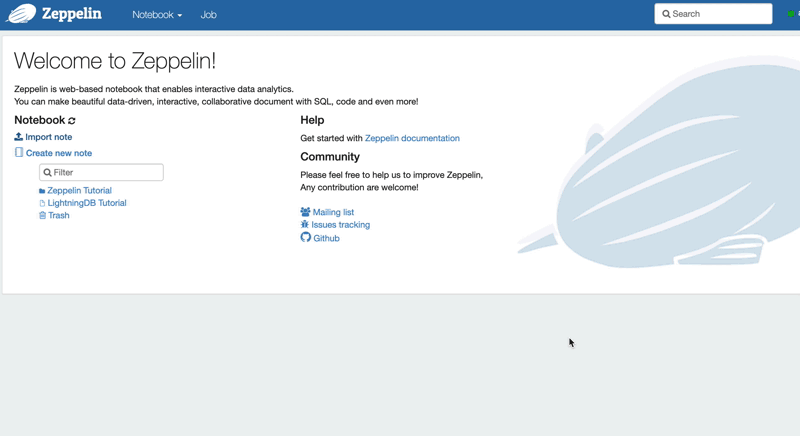
You can import the tutorial notebook with its URL.
https://raw.githubusercontent.com/mnms/tutorials/master/zeppelin-notebook/note.json
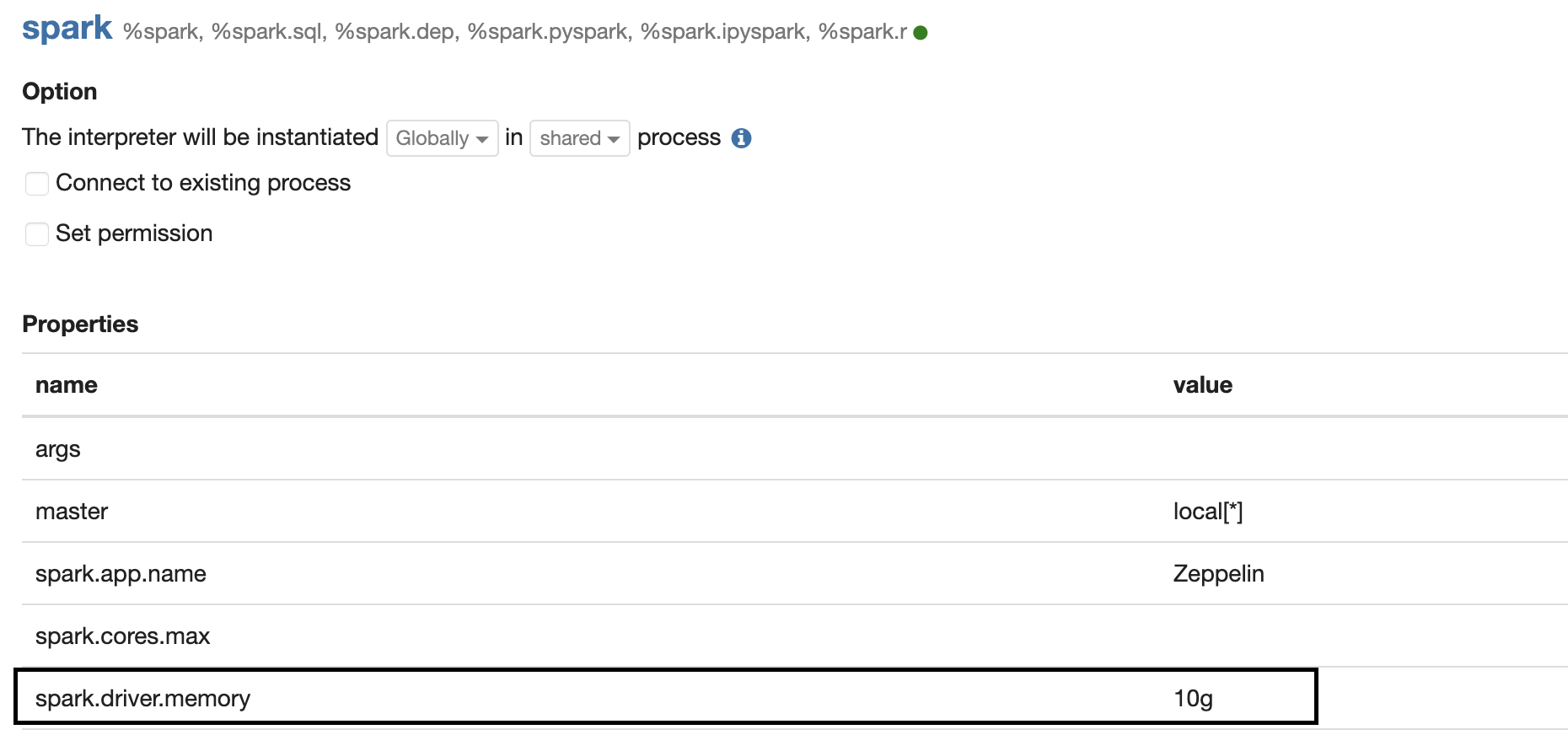
The tutorial runs on the spark interpreter of Zeppelin. Please make sure that the memory of the Spark driver is at least 10GB in the Spark interpreter setting.
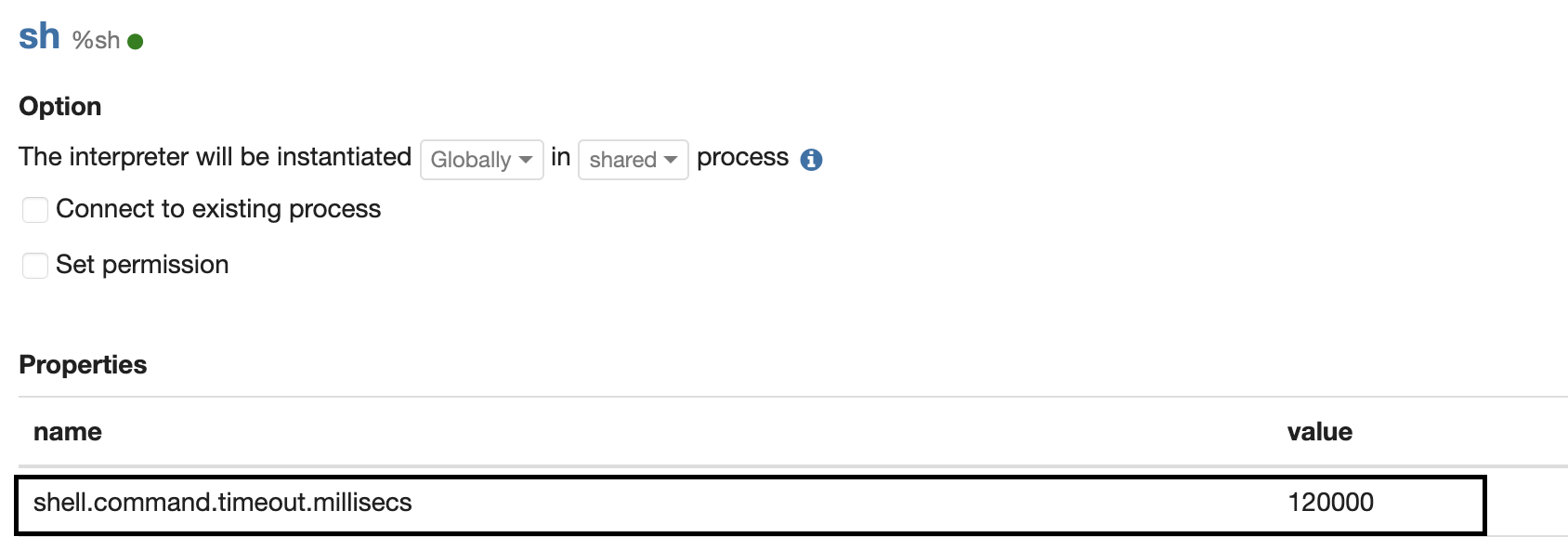
Also, make sure that the timeout of a shell command is at least 120000 ms.